
Навигация по странице
О задании
Задание 16 ЕГЭ по информатике нацелено на проверку умений работать с рекурсивными алгоритмами. В этом задании вам даётся некая функция, заданная соотношениями, значение которой необходимо вычислить. Функция рекурсивная, то есть вычисление следующего значения опирается на значение этой же функции, полученное при вычислении предыдущего значения.
Для решения таких заданий можно использовать 4 подхода: ручное решение, решение итеративным методом, решение через увеличение глубины рекурсии и решение с использованием мемоизации.
В этой статье мы изучим работу рекурсии в языке Python, познакомимся с понятием кеширования значений функции, научимся работать с декораторами и разберем алгоритмы решения заданий 16 всеми четырьмя методами.
Рекурсия
Рекурсия – это процесс, при котором функция (или алгоритм) вызывает саму себя. В программировании это означает, что такая функция решает какую-то большую задачу, разбивая её на более мелкие подзадачи того же типа.
Например, вспомним, как вычисляется факториал числа. Факториал некоторого числа n! – это произведение всех натуральных чисел от 1 до n. Вот скажите, как вы будете вычислять факториал 5?
Очевидно, для того чтобы посчитать факториал 5, мы должны умножить само число 5 на факториал 4. Для вычисления факториала 4 – умножаем 4 на факториал 3 и так далее. Это будет продолжаться до единицы, факториал которой равен самому себе, то есть числу 1.
Таким образом, мы разбиваем сложную и большую задачу вычисления факториала 5 на более мелкие: вычисление произведения рассматриваемого числа на факториал предыдущего.
Выразить факториал можно так:


В этой формуле произведение числа n на факториал предыдущего (n × (n-1)!) называется рекурсивным случаем. А 1!= 1 – базовым. Базовый случай как раз необходим, чтобы остановить рекурсию и прекратить бесконечный цикл вызовов.
Можно сделать такой вывод:
- Базовый случай – это условие, при котором рекурсия останавливается. Без базового случая функция будет вызывать саму себя бесконечно
- Рекурсивный случай – это шаг, на котором функция вызывает саму себя, приближаясь к базовому случаю
Теперь рассмотрим, как рекурсия реализуется в программировании.
Для начала нам необходимо создать рекурсивную функцию – такую, внутри которой будет вызов этой же функции. В нашей задаче про факториал функция может выглядеть так:
def factorial(n):
# Базовый случай
if n == 1:
return 1
# Рекурсивный случай
else:
return n * factorial(n - 1)
Когда вызывается рекурсивная функция, она помещает текущий контекст выполнения в стек вызовов. Контекст выполнения включает в себя информацию о локальных переменных (здесь – n), аргументах функции и месте возврата.
Стек вызовов представляет собой структуру данных, в которой хранится информация о вызовах функций. Допустим, у нас есть функция A(), которая вызывает функцию B(), которая, в свою очередь, вызывает уже другую функцию – C().
В коде это можно записать так:
def A():
B()
def B():
C()
def C():
pass
Графически эти вызовы можно представить следующим образом:

Теперь вызовем функцию А(). Что в это время произойдёт в нашей программе?
Вызов каждой функции помещается в стек. Его можно представить как некий список, в который последовательно попадают вызовы функций: снизу первый вызов, сверху – последний.
То есть мы помещаем в него вызовы, как в обычную банку: сначала что-то попадает на дно банки и постепенно она заполняется все новым и новым содержимым.

Сначала мы вызываем функцию А() – этот вызов становится первым элементом стека. Затем функция А() вызывает B(), вызов которой уже будет вторым элементом в стеке. Ну и вызов функции С() будет третьим и последним элементом нашего стека вызовов.
Стек – это структура данных, которая работает по принципу LIFO (last in – first out) «последним зашёл – первым вышел».
То есть первой будет исполняться последняя вызванная функция.
Вернёмся к нашим рекурсивным функциям. Каждый вызов функции будет помещаться в стек со всем своим контекстом выполнения. И так будет происходить до тех пор, пока не будет достигнут базовый случай.
То есть в нашем примере на самой верхушке стека будет функция factorial(1), которая возвращает 1. Система вызывает её, получает в результате единицу, следом вызывается функция factorial(2), затем factorial(3) и так до исходной функции factorial(5).

Но стек вызовов не бесконечен. В каждом языке программирования накладываются свои ограничения на стек. К тому же в самой операционной системе есть собственные ограничения на стек вызовов.
Таким образом, если у вас будет слишком много вызовов функции, то произойдёт переполнение стека (stack overflow), что приведёт к аварийному завершению процесса.
В Python стек вызовов по умолчанию ограничен значением в 1000 вызовов. То есть максимальная глубина рекурсии (количество вызовов рекурсивной функции) достигается при значении в 1000 вызовов.
Например, если мы попытаемся вычислить факториал 1000, то увидим такое сообщение от интерпретатора «RecursionError: maximum recursion depth exceeded». Это означает, что мы достигли максимальной глубины рекурсии.
Но не будем верить на слово этому ограничению и проверим, какая же установлена максимальная глубина рекурсии. Для этого необходимо вызвать функцию getrecursionlimit из модуля sys.
Следующий код вернёт нам значение глубины рекурсии – 1000:
import sys
print(sys.getrecursionlimit())
>>>1000
Но как быть, если нам уж очень хочется посмотреть, какой же там будет факториал у числа 1000? Есть два подхода к решению этой задачи (если никак нельзя уйти от рекурсии): увеличить глубину рекурсии или использовать мемоизацию. Оба подхода мы рассмотрим далее. Но начнём с увеличения глубины рекурсии.
Да, самое очевидное, что может прийти на ум – просто убрать ограничения, установленные разработчиками языка, тем более что они предоставили такую удобную функцию для этого. Этой функцией является setrecursionlimit из того же модуля sys.
Эта функция принимает целое число и изменяет внутренний счётчик, который отслеживает глубину рекурсии. Например, установим максимальную глубину рекурсии на значение 1001 и вычислим факториал:
import sys
sys.setrecursionlimit(1001)
def factorial(n):
if n == 1:
return 1
else:
return n * factorial(n - 1)
print(factorial(1000))
Такое увеличение глубины рекурсии не гарантирует, что программа будет работать корректно. Если глубина рекурсии слишком большая, это может привести к переполнению стека и аварийному завершению программы.
То есть, теоретически мы можем установить какое-либо большое значение максимальной глубины рекурсии, например, 1000000, Python спокойно разрешит это сделать.
Но в таком случае нам уже «прилетит» от операционной системы. Во-первых, она ограничивает размер стека вызовов для каждого процесса. Выход за пределы этого стека приведёт к аварийному завершению процесса с системной ошибкой Segmentation Fault (ошибка сегментации).
Во-вторых, глубокая рекурсия требует много памяти. В таком случае либо ваша программа будет работать очень долго (если памяти много), либо завершится с системной ошибкой Out of Memory (нехватка памяти).
Правда, на деле, все подобные ошибки уже учтены при разработке языка Python и отлавливаются интерпретатором. На работу операционной системы это никак не повлияет, она просто завершит проблемный процесс.
Так что лучше не злоупотреблять увеличением максимальной глубины рекурсии и воспользоваться мемоизацией.
Мемоизация
Мемоизация – это техника оптимизации, направленная на повышение производительности функций путём сохранения результатов их выполнения для повторного использования при одинаковых входных данных.
Мемоизация основана на простой идее: если у нас есть функция, которая вызывается с одними и теми же аргументами и возвращает всегда один и тот же результат, то её значения целесообразно где-то сохранять. При этом вместо повторного вычисления результата этой функции мы просто можем взять это значение из памяти.
Например, при вычислении факториала 5 мы опираемся на значения факториалов предыдущих чисел. Так зачем нам каждый раз вычислять какой-нибудь факториал 2, если можем просто сохранить это значение в какой-то переменной и подставлять его в выражение?
Значения эти сохраняются не просто в какую-то переменную, а хранятся в кеше. А что вообще такое кеш?
Вы с ним сталкиваетесь каждый день, но при этом можете даже не подозревать о его работе. Разберем самый типичный пример использования кеша – кеширование страниц веб-сайтов.
При первом заходе на сайт у нас загружаются все медиа объекты, тексты и интерактивные элементы. Это может занимать определённое время, в течение которого вместо всех этих объектов вы видите некоторые «заглушки» (незагруженные изображения, анимации и т.д.).
Но, если на таком сайте подключено кеширование, при повторном посещении этой же страницы она будет грузиться гораздо быстрее. Это происходит как раз из-за того, что все необходимые объекты не скачиваются с удалённого сервера, а загружаются напрямую из кеша вашего браузера. Таким образом, мы получаем ускорение доступа к данным за счет кеширования.
Или можем рассмотреть такой пример: пользователь запрашивает у приложения какие-то данные из базы данных. Что при этом происходит внутри приложения?
Сначала запрос пользователя отправляется в приложение, оно уже обращается к базе данных за необходимыми данным. Данные из базы попадают в приложение и возвращаются к пользователю.
Но если подключить кеширование в это приложение, то данные будут не сразу отправляться к пользователю, а сохранятся в некотором промежуточном хранилище – кеше приложения.
В таком случае при следующем обращении пользователя за этими же данными ему не придётся так долго ждать, пока приложение запросит данные у базы. Ведь они уже сохранены в кеше, и их можно сразу же отправить пользователю.

Чтобы не запутаться в терминах «кеширование» и «мемоизация», запомните следующее:
- Мемоизация – это частный случай кеширования, который применяется для оптимизации вычислений в функциях.
- Кеширование – это более общая техника, которая используется для ускорения доступа к данным на разных уровнях.
Обе техники помогают улучшить производительность программ, но применяются в разных ситуациях. Мемоизация идеальна для оптимизации функций (наш случай), а кеширование – для работы с данными, которые редко меняются, но часто запрашиваются (примеры выше – веб-страницы или обращение к базе данных).
Теперь с пониманием работы кеша вернёмся к мемоизации. Мы уже понимаем, что использование мемоизации помогает при работе с рекурсивными функциями.
Давайте проверим работу мемоизации на другом примере. Еще одним классическим примером рекурсивной функции является вычисление чисел Фибоначчи.
Вспомним, как вычисляется n-ый элемент ряда Фибоначчи: F(n)=F(n−1)+F(n−2).
Для нахождения, например, пятого элемента нам необходимо:
- Определить значение третьего и четвертого элемента.
- Для получения четвертого элемента требуется найти значение третьего и второго.
- Снова определить значение третьего, для чего необходимо повторно найти значение второго и значение первого (оно уже известно и равно 1).
И так мы будем определять 2 раза значение третьего элемента и 3 раза значение второго.
Можно написать такую рекурсивную функцию для вычисления значения n-го элемента ряда Фибоначчи:
def fib(n):
if n < 2:
return n
return fib(n - 2) + fib(n - 1)
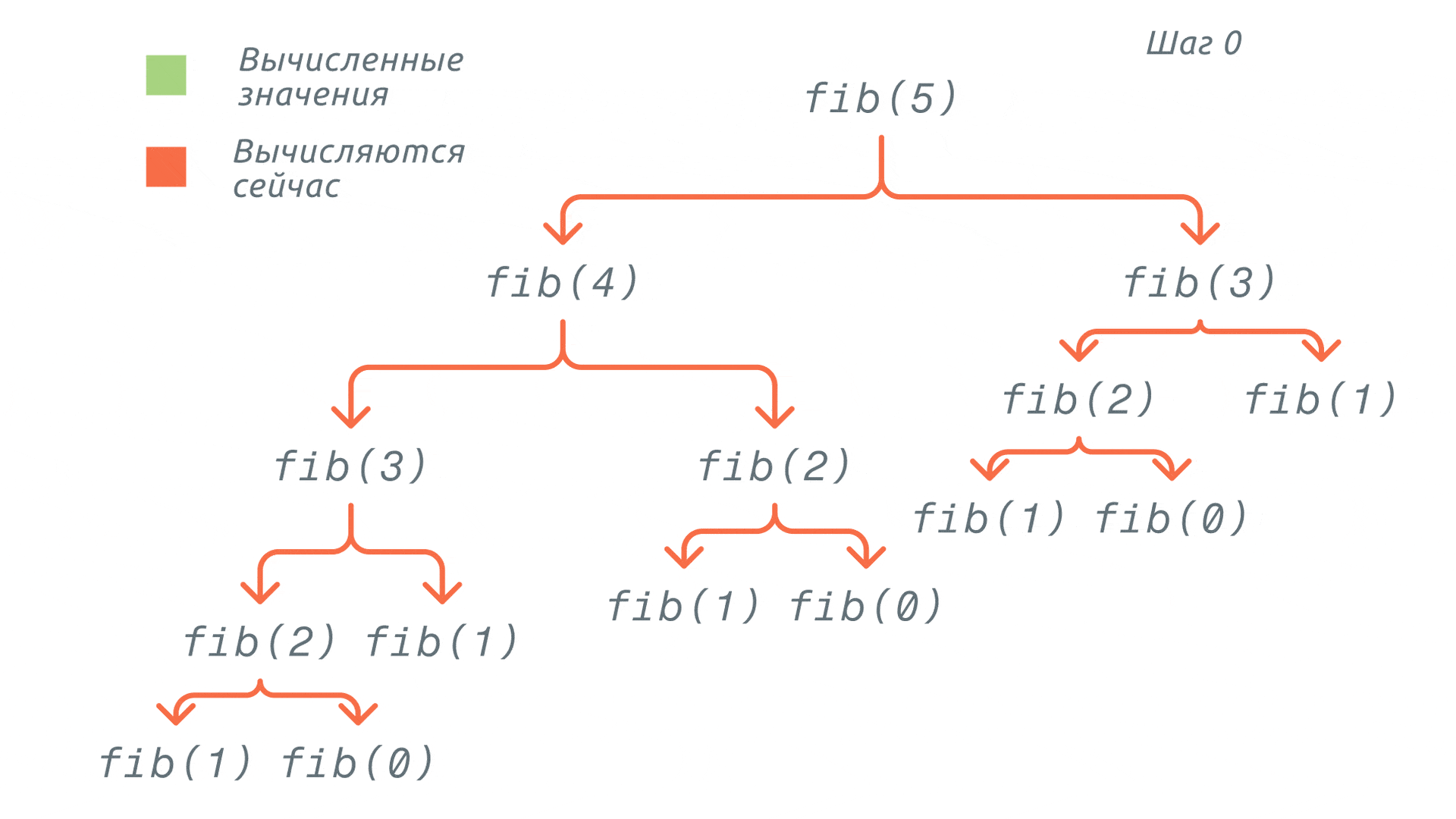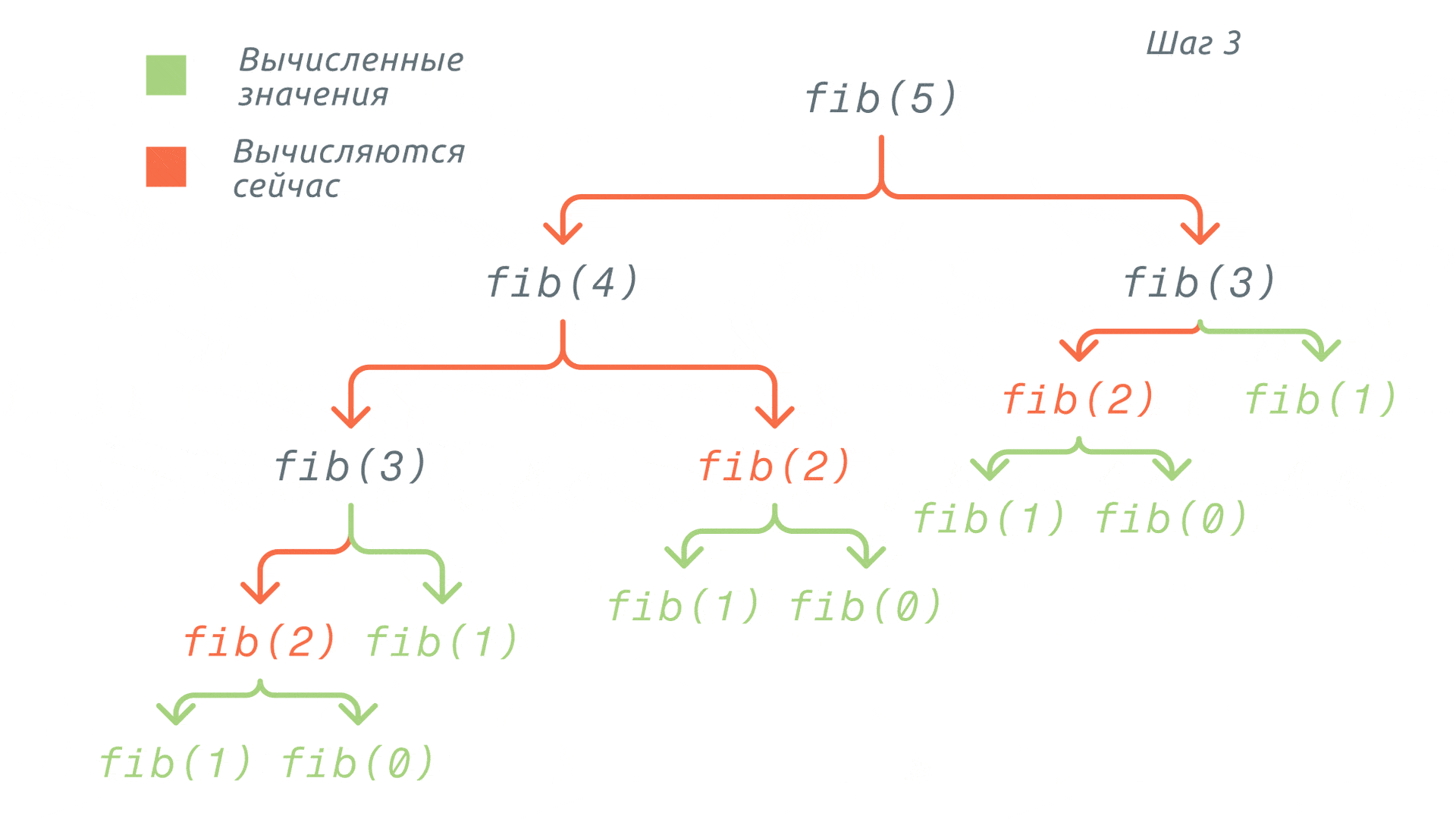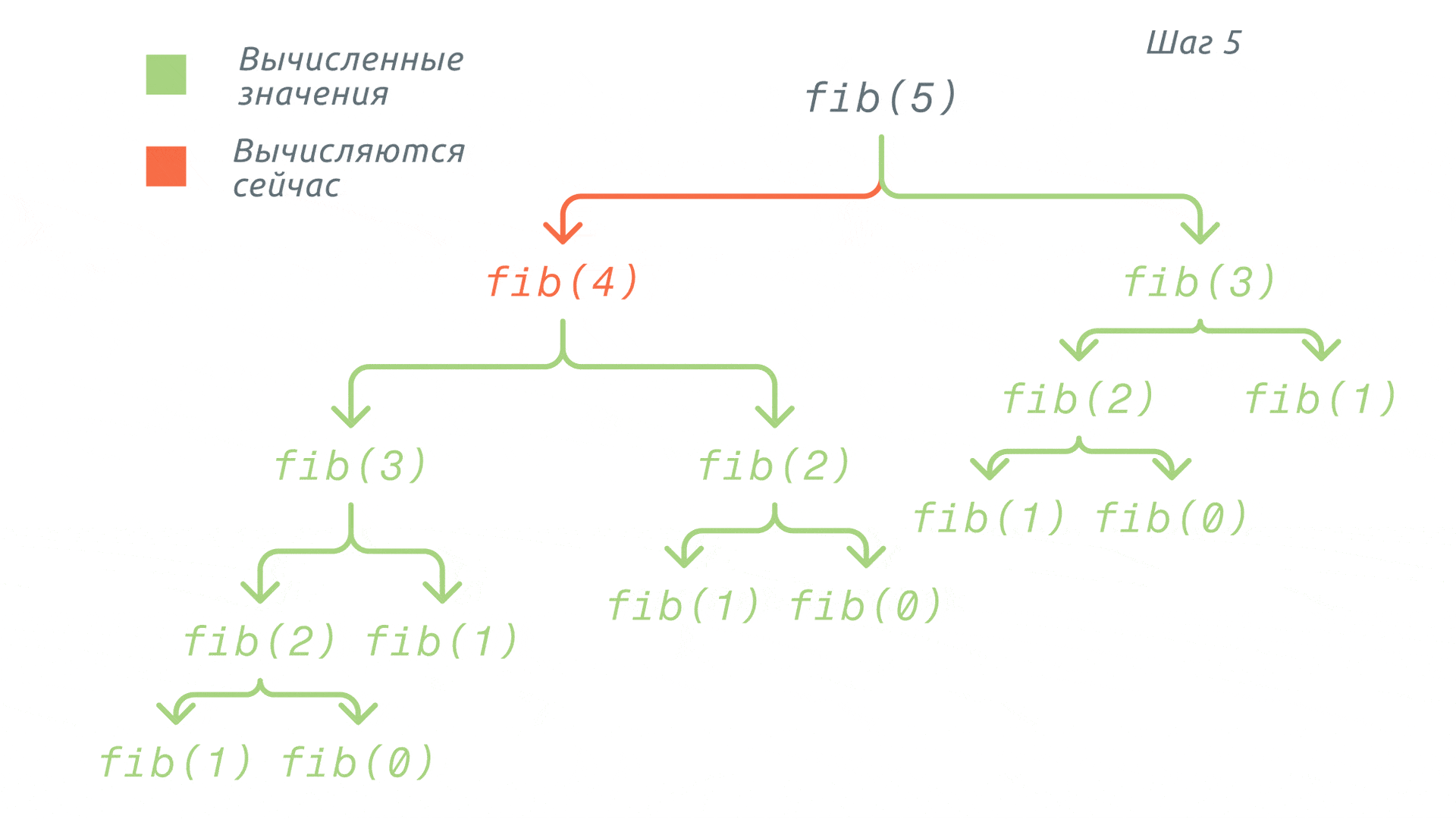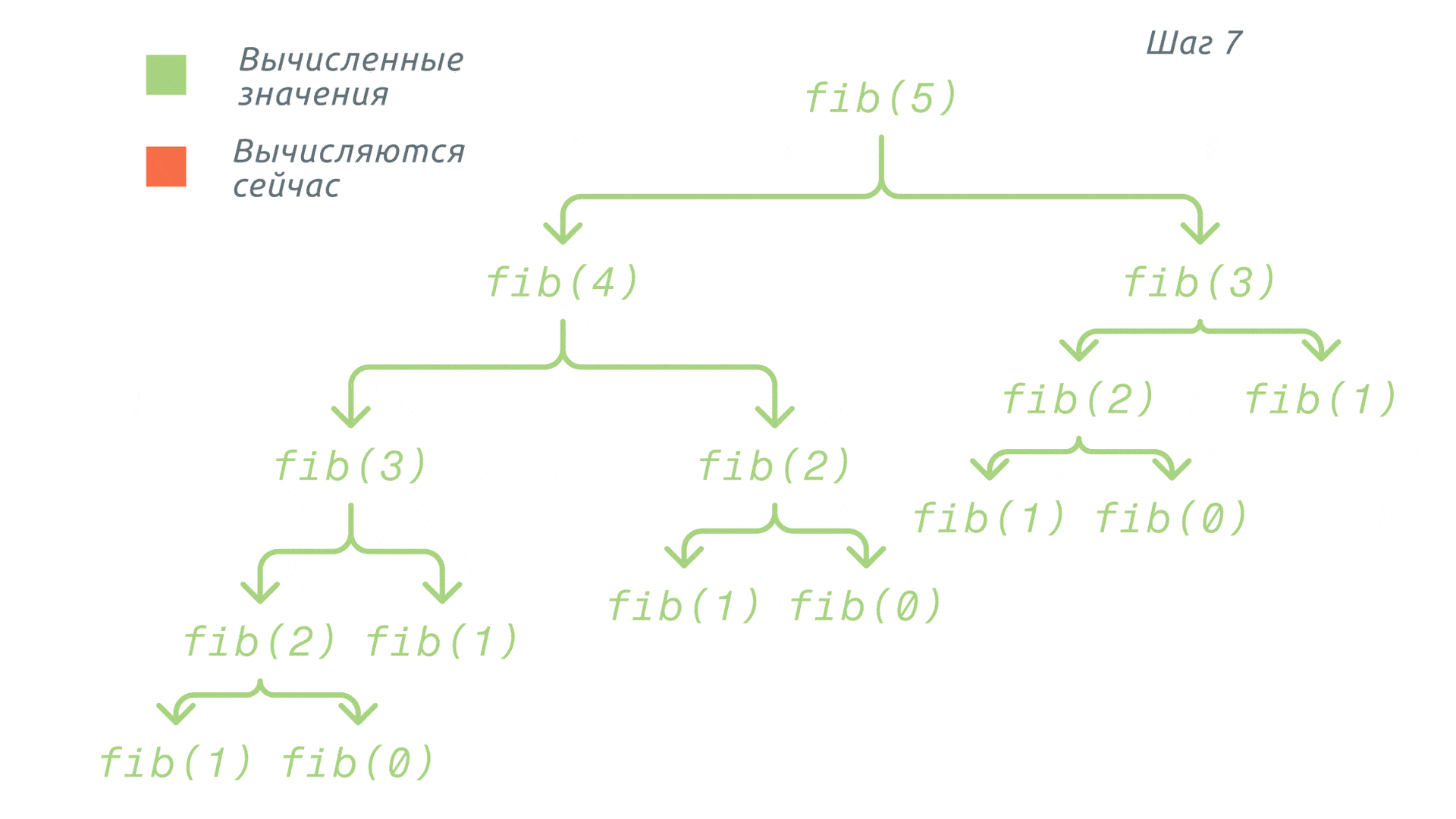
Тогда вызов функции fib(5) можно представить в виде такого дерева:

Обратите внимание, сколько раз мы вычисляем значение fib(0) и fib(1). И это только для пятого элемента ряда Фибоначчи. Каждый повторный вызов функции будет увеличивать время работы программы.
Для примера давайте вычислим 35 элемент ряда Фибоначчи просто рекурсивной функцией, без какой-либо мемоизации:
import time
def fib(n):
if n < 2:
return n
return fib(n - 1) + fib(n - 2)
# Замеряем время выполнения
start = time.perf_counter()
print(f'35 элемент ряда Фибоначчи: {fib(35)}')
end = time.perf_counter()
e_time = f'{(end - start) * 10 ** 3:.3f}'
print(f'Время выполнения: {e_time} миллисекунд')
>>>35 элемент ряда Фибоначчи: 9227465
>>>Время выполнения: 3157.243 миллисекунд
Довольно долго, не так ли? Теперь применим к этой программе мемоизацию. То есть мы будем добавлять в кеш (в нашем случае – просто в словарь) значения уже вычисленных элементов.
Получается, что мы доходим до вызова функции fib(0) и добавляем её результат в словарь. Аналогично будет и с fib(1). Далее для вычисления значения fib(2) мы уже не будем вызывать функции fib(1) и fib(0), а просто возьмём значения из нашего словаря.
И так будем проделывать с каждой функцией вплоть до нужного значения. Таким образом, значительно снизим не только количество вызовов функций, но и время выполнения всей программы. Весь этот процесс проиллюстрирован ниже:
Давайте реализуем это в коде. Алгоритм у нас будет следующий:
- Создание кеша. В нашем случае это будет просто словарь, в который мы помещаем результаты работы функций. Ключами в словаре будут аргументы функции.
- Проверка кеша. При вызове функции проверяем, есть ли в словаре значение с ключом, равным аргументу функции.
- Если значение в кеше найдено – возвращаем его. Если нет, то вычисляем.
- После вычисления возвращаем полученное значение, перед этим сохранив его в кеше.
В итоге получаем такую программу:
import time
fib_cache = {}
def fib_caсhed(n):
# Проверка, есть ли значение в кеше
if n in fib_cache:
return fib_cache[n]
# Базовые случаи
if n < 2:
return n
result = fib_caсhed(n - 1) + fib_caсhed(n - 2)
# Сохранение результата в кеш
fib_cache[n] = result
return result
# Замеряем время выполнения
start = time.perf_counter()
print(f'35 элемент ряда Фибоначчи: {fib_caсhed(35)}')
end = time.perf_counter()
e_time = f'{(end - start) * 10 ** 3:.3f}'
print(f'Время выполнения: {e_time} миллисекунд')
>>>35 элемент ряда Фибоначчи: 9227465
>>>Время выполнения: 0.046 миллисекунд
То есть, используя мемоизацию, мы ускорили работу программы примерно в 68 000 раз!
Всю логику работы мемоизации можно поместить в отдельную функцию и создать из неё декоратор:
# --- Декоратор мемоизации --- #
def cached(func):
cache = {}
def decorate(*args):
if args in cache:
return cache[args]
else:
cache[args] = func(*args)
return cache[args]
return decorate
Поздравляем, теперь у вас есть собственный декоратор для мемоизации! Однако есть более оптимизированный подход. Вместо того чтобы создавать свой декоратор – использовать готовый декоратор @lru_cache из модуля functools.
Декоратор @lru_cache
Сначала давайте разберёмся, что вообще означает название lru_cache. С кешем мы уже знакомы, теперь настало время понять назначение этих трёх букв – LRU.
Дело в том, что LRU – это стратегия вытеснения кеша. Мы уже знаем, что память в компьютере не бесконечна, следовательно, хранить в кеше абсолютно все значения мы не можем. Но как понять, от каких можно избавиться, а какие нам еще пригодятся? Тут на помощь и приходят стратегии вытеснения.
Стратегии вытеснения кеша определяют механизм, по которому данные удаляются из кеша, когда он достигает своего максимального размера. Под каждую задачу выбирается определённая стратегия вытеснения, что обеспечивает необходимую производительность работы.
Оптимальная стратегия минимизирует количество промахов кеша (ситуаций, когда запрошенных данных нет в кеше – cache miss) и максимизирует эффективность использования доступной памяти.
Наиболее распространенные стратегии вытеснения кеша перечислены ниже:
- FIFO (First-In-First-Out): удаляет самый старый элемент, добавленный в кеш
- LRU (Least Recently Used): удаляет элемент, который не использовался дольше всего
- LFU (Least Frequently Used): удаляет элемент, который используется реже всего
- TLRU (Time-aware Least Recently Used): добавляет понятие времени жизни к LRU
- Random Replacement: удаляет случайный элемент из кеша
Стратегия LRU основана на предположении о том, что, если элемент был недавно запрошен, существует высокая вероятность того, что он понадобится снова в ближайшем будущем.
Следовательно, такой элемент важен и удалять его с кеша нельзя. Значит, при необходимости освободить место в кеше следует удалять те элементы, которые не были востребованы дольше всего.
Работа LRU-кеша начинается с определения максимального количества элементов, которые могут одновременно храниться в кеше. Это значение выбирается исходя из доступных ресурсов и требований к производительности.
Слишком маленький кеш будет часто опустошаться, а слишком большой кеш может потреблять избыточное количество памяти и замедлять работу системы.
В основе внутренней структуры LRU-кеша лежит комбинация двух ключевых компонентов: хеш-таблицы (словаря) для быстрого доступа к элементам по ключу и двусвязного списка для отслеживания порядка использования элементов.
Хеш-таблица обеспечивает операции поиска, вставки и удаления элементов за константное время O(1), а двусвязный список позволяет эффективно перемещать элементы и поддерживать их упорядоченность.
Когда мы обращаемся к существующему элементу в кеше, происходит сразу несколько операций. Во-первых, проверяется наличие запрашиваемого ключа в хеш-таблице. Если ключ найден, то возвращается значение элемента из кеша.
Во-вторых, соответствующий элемент (узел) двусвязного списка перемещается в начало. Это будет означать факт недавнего использования элемента. То есть в начале списка у нас всегда те элементы, которые использовались недавно, а в конце – те, что использовались давно.
Это все происходит, если элемент уже есть в кеше. Теперь же рассмотрим ситуацию, когда такого элемента в кеше нет. Тогда, сначала проверяется, существует ли элемент с таким ключом. Если элемент существует, то его значение обновляется, а узел двусвязного списка перемещается в начало.
Если такого элемента нет, создается новый узел, который добавляется в начало списка, а соответствующая запись вносится в хеш-таблицу.
Критический момент наступает, когда кеш достигает своей максимальной емкости, а новый элемент как-то надо добавить. В этом случае как раз и активируется стратегия вытеснения: из конца двусвязного списка удаляется элемент и соответствующая запись в хеш-таблице. Тем самым освобождается место для нового элемента.
Но на деле вам знать все эти тонкости работы стратегии вытеснения кеша не обязательно. За вас уже реализовали весь функционал и поместили его в удобную форму – декоратор @lru_cache из модуля functools.
Декоратор @lru_cache может принимать два параметра:
1. Параметр maxsize (по умолчанию 128) – отвечает за максимальное количество кешируемых результатов. После достижения этого предела наименее недавно использованные результаты будут удалены для освобождения места новым. Значение аргумента должно быть целым положительным числом.
Если установить maxsize=None, кеш будет расти неограниченно, что потенциально может привести к проблемам с памятью при длительном использовании или при обработке большого количества уникальных входных данных.
Значение maxsize рекомендуется устанавливать как степень двойки для оптимальной производительности, так как внутренняя реализация использует битовые операции для ускорения доступа.
2. Параметр typed (по умолчанию False) – отвечает за тип данных кешируемых результатов. Если параметр typed принимает значение True, то тогда декоратор различает кешированные результаты для различных типов данных.
Например, при typed=True вызовы function(1) и function(1.0) будут считаться разными и кешироваться отдельно, несмотря на то, что их значения математически эквивалентны.
После применения декоратора lru_cache декорируемая функция получает следующие дополнительные методы:
Метод cache_info() возвращает именованный кортеж с информацией о текущем состоянии кеша:
- hits: количество успешных обращений к кешу (когда результат был найден)
- misses: количество неудачных обращений (когда результат пришлось вычислять)
- maxsize: максимальный размер кеша
- currsize: текущее количество элементов в кеше
Эта информация может быть полезна для анализа эффективности кеширования и настройки параметра maxsize.
Метод cache_clear() полностью очищает кеш, удаляя все сохраненные результаты. Это может быть полезно при изменении внешних ресурсов, от которых зависит функция, или для освобождения памяти.
Давайте продемонстрируем его работу все на той же функции для вычисления n-го элемента ряда Фибоначчи:
import time
from functools import lru_cache
@lru_cache()
def fib(n):
if n < 2:
return n
return fib(n - 1) + fib(n - 2)
# Замеряем время выполнения
start = time.perf_counter()
print(f'35 элемент ряда Фибоначчи: {fib(35)}')
end = time.perf_counter()
e_time = f'{(end - start) * 10 ** 3:.3f}'
print(f'Время выполнения: {e_time} миллисекунд')
>>> 35 элемент ряда Фибоначчи: 9227465
>>>Время выполнения: 0.088 миллисекунд
Теперь смело можем переходить к разбору алгоритма решения задания 16 ЕГЭ по информатике.
Алгоритм решения
В задании 16 нам необходимо сделать буквально 2 действия: правильно переписать функцию, заданную в условии, и применить нужную оптимизацию, если мы решаем программным методом.
Как мы уже говорили в начале, есть 4 способа решения этих заданий – ручной, итеративный (без рекурсии) и 2 способа с рекурсией: с увеличением максимальной глубины и с использованием мемоизации.
Далее мы рассмотрим решение всеми четырьмя способами, но большее внимание уделим именно решению с использованием декоратора @lru_cache как самому эффективному и надёжному.
Ручное решение
Задание 1600
«Алгоритм вычисления значения функции F(n), где n – натуральное число, задан следующими соотношениями:
F(n)=n при n>2024;
F(n)=n×F(n+1), если n≤2024
Чему равно значение выражения F(2022)/ F(2024)?»
Откровенно говоря, тут особенно много вызовов рекурсии-то и не будет. Так что кодом это решается без всякой оптимизации, но куда быстрее будет решить такое задание вручную.
Давайте сразу вычислим значение функции F(2022):
F(2022) = 2022 * F(2023)
F(2023) = 2023 * F(2024)
Значит, F(2022) можно вычислить так: 2022 * 2023 * F(2024)
И тут сделаем остановку. Дело в том, что в ответ нас просят дать отношение F(2022)/ F(2024), но мы сразу видим, что здесь можно сократить эту дробь на значение функции F(2024):

Вот и все, мы получили ответ на это задание: 4090506.
Итеративный подход
Большую часть официальных заданий 16 можно решать ручным способом, даже не написав ни одной строчки кода. Но все же, давайте рассмотрим случай, если вам очень не хочется ни считать, ни работать с рекурсией.
В таком случае можно переписать функцию таким образом, чтобы исключить рекурсивный вызов функции, заменив его на итеративное вычисление каждого значения. Мы будем сохранять каждое значение функции в список, а в цикле вычислять значения вплоть до необходимого.
Рассмотрим такую формулировку:
Задание 1601
«Алгоритм вычисления значения функции F(n), где n – натуральное число, задан следующими соотношениями:
F(n)=1 при n≤3;
F(n)=(n+3)×F(n−2), если n>3.
Чему равно значение выражения F(2028)/F(2024)?»
Итак, при значениях n ≤ 3 функция будет выдавать в качестве результата число 1. Можем сразу записать эти значения в список:
cache = [1, 1, 1, 1]
Далее будем в цикле добавлять к этому списку значения по формуле из условия:
for i in range(4, n + 1):
cache.append((i + 3) * cache[i - 2])
Теперь оформим все это в виде обычной функции:
def f_iter(n):
if n <= 3:
return 1
cache = [1, 1, 1, 1]
for i in range(4, n + 1):
cache.append((i + 3) * cache[i - 2])
return cache[n]
Ответ получим из такой записи:
print(f_iter(2028) // f_iter(2024))
В результате на экране видим число: 4120899, которое и будет ответом на это задание.
Увеличение глубины рекурсии
Если вы все же хотите решать это задание с использованием рекурсии, то можно использовать увеличение глубины рекурсии с помощью функции sys.setrecursionlimit().
При таком подходе мы сначала вызываем sys.setrecursionlimit(), а затем переписываем функцию из условия задания.
Формулировка здесь будет следующая:
Задание 1602
«Алгоритм вычисления значения функции F(n), где n – натуральное число, задан следующими соотношениями:
F(n)=1 при n=1;
F(n)=(n−1)×F(n−1), если n>1.
Чему равно значение выражения (F(2024)+2×F(2023))/F(2022)?»
Нам следует увеличить максимальную глубину рекурсии до значения 2025:
import sys
sys.setrecursionlimit(2025)
Далее переписываем функцию из условия:
def f(n):
if n == 1:
return 1
else:
return (n - 1) * f(n - 1)
И в конце в print() записываем самое выражение. Здесь самое главное – это правильно расставить скобки в выражении:
print((f(2024) + 2 * f(2023)) // f(2022))
Полный код для решения этого задания будет таким:
import sys
sys.setrecursionlimit(2025)
def f(n):
if n == 1:
return 1
else:
return (n - 1) * f(n - 1)
print((f(2024) + 2 * f(2023)) // f(2022))
В ответ записываем число 4094550.
Решение с мемоизацией
Подход к решению с использованием мемоизации будет немного отличаться от подхода с увеличением глубины рекурсии. Здесь нам необходимо будет в цикле вызвать функцию, передавая ей в качестве аргумента целые числа из определённого диапазона. Формировать диапазон мы будем на основе базового случая и максимального аргумента рекурсивной функции.
Задание 1603
«Алгоритм вычисления значения функции F(n), где n – целое число, задан следующими соотношениями:
F(n)=n, если n<5,
F(n)=2n×F(n−4), если n≥5.
Чему равно значение функции (F(13766)−9×F(13762))/F(13758)?»
Импортируем lru_cache из модуля functools и декорируем нашу функцию:
from functools import lru_cache
@lru_cache()
def f(n):
if n < 5:
return n
return 2 * n * f(n - 4)
Далее в цикле запускаем функцию со аргументами из числового диапазона от 5 до 13766 (включительно):
for n in range(5, 13767):
f(n)
И выводим результат выражения из условия:
print((f(13766) - 9 * f(13762)) // f(13758))
Весь код будет такой:
from functools import lru_cache
@lru_cache()
def f(n):
if n < 5:
return n
return 2 * n * f(n - 4)
for n in range(5, 13767):
f(n)
print((f(13766) - 9 * f(13762)) // f(13758))
По окончании работы программы получаем ответ на данное задание: 757543052
И рассмотрим еще один пример с подобным решением.
Задание 1604
«Алгоритм вычисления значения функции F(n), где n – натуральное число, задан следующими соотношениями:
F(n)=1 при n=1;
F(n)=2×n×F(n–1), если n>1.
Чему равно значение выражения (F(2024)/16−F(2023))/F(2022)?»
Подробно останавливаться на разборе каждого блока кода не будем, решение здесь аналогично предыдущему:
from functools import lru_cache
@lru_cache
def f(n):
if n == 1:
return 1
return 2 * n * f(n - 1)
for n in range(1, 2026):
f(n)
print((f(2024) // 16 - f(2023))//f(2022))
В результате получаем ответ на это задание: 1019592.